Data Augmentation has proved to be an effective method for classification of images. It significantly increases the diversity of data available for training our models, without actually collecting new data samples. In this project, we have looked on recently proposed augmentation techniques popularly known as MixUp, CutMix, AugMix and CutOut. We found that models trained using augmentation techniques are calibrated more better. Ensemble models consisting of deep Convolutional Neural Networks (CNN) have shown significant improvements in model generalization but at the cost of large computation and memory requirements. We try to distillate all of the augmentation techniques in different teacher models and combine the knowledge of all the well calibrated teacher models into one shallow well calibrated student model.
-
MixUp: In this augmentation technique, samples are generated during training by convexly combining random pairs of images and their associated labels. Hence, we can say that the classifier is trained not only on the training data, but also in the vicinity of each training sample. -
CutMix: CutMix is an augmentation strategy incorporating region-level replacement. For a pair of images, patches from one image are randomly cut and pasted onto the other image along with the ground truth labels being mixed together proportionally to the area of patches. CutMix replaces the removed regions with a patch from another image, which utilizes the fact that there is no uninformative pixel during training, making it more efficient and effective. -
CutOut: Cutout augmentation is a kind of regional dropout strategy in which a random patch from an image is zeroed out (replaced with black pixels). Cutout samples suffer from the decrease in information. -
AugMix: AugMix is a data processing technique which mixes randomly generated augmentations, improves model robustness and slots easily existing training pipelines. Augmix performs data mixing using the input image itself. It transforms (translate, shear, rotate and etc) the input image and mixes it with the original image. AugMix prevents degradation of images while maintaining diversity as a result of mixing the results of augmentation techniques in a convex combination.
Knowledge distillation is the process of transferring knowledge from a large model to a smaller one. While large models (such as very deep neural networks or ensembles of many models) have higher knowledge capacity than small models, this capacity might not be fully utilized. It can be computationally just as expensive to evaluate a model even if it utilizes little of its knowledge capacity. Knowledge distillation transfers knowledge from a large model to a smaller model without loss of validity. As smaller models are less expensive to evaluate, they can be deployed on less powerful hardware (such as a mobile device).
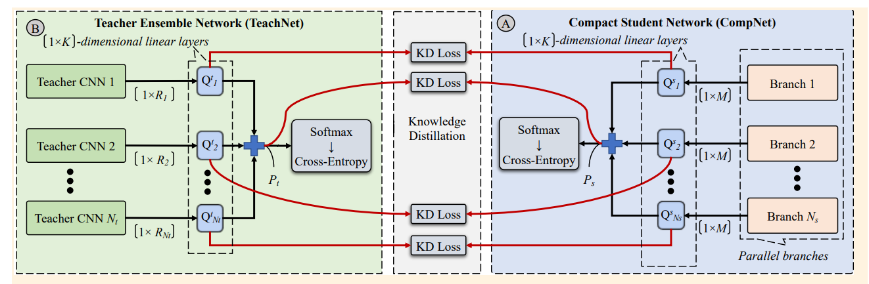
We present an Ensemble Knowledge Distillation (EKD) framework which improves classification performance and model generalization of small and compact networks by distilling knowledge from multiple teacher networks into a compact student network using an ensemble architecture.
Dataset used : CIFAR100
Performance metrices used to compare results - Accuracy, Expected Calibration Error, Overconfidence Error
Teacher Model : Wide Resnet 40-2
| Technique | Best Accuracy | ECE | OE |
|---|---|---|---|
| Without | 75.63 | 0.1104 | 0.0893 |
| MixUp | 76.98 | 0.0351 | 0.0027 |
| CutMix | 78.54 | 0.0315 | 0.0186 |
| CutOut | 77.31 | 0.0775 | 0.0591 |
| Augmix | 76.66 | 0.0437 | 0.0300 |
| Calibration Ensemble | 80.26 | 0.0306 | 0.0044 |
Student Model : Shufflenet V1
| Technique | Best Accuracy | ECE | OE |
|---|---|---|---|
| Without | 71.45 | 0.0890 | 0.0646 |
| Technique | Best Accuracy | ECE | OE |
|---|---|---|---|
| Vanilla KD | 75.41 | 0.1200 | 0.0992 |
| KD with mixup | 74.48 | 0.0399 | 0.0235 |
| KD with cutmix | 74.62 | 0.0552 | 0.0357 |
| KD with augmix | 75.72 | 0.0781 | 0.0605 |
| KD with cutout | 75.93 | 0.0969 | 0.0775 |
| Technique | Best Accuracy | ECE | OE |
|---|---|---|---|
| KD Ensemble (add loss) | 77.28 | 0.0610 | 0.0460 |
| KD Ensemble (avg loss) | 75.71 | 0.0752 | 0.0563 |
| KD Ensemble (avg softmax) | 75.55 | 0.0707 | 0.0522 |
Accuracy : 77.47
ECE : 0.0282
OE : 0.0146